これは、このセクションの複数ページの印刷可能なビューです。 印刷するには、ここをクリックしてください.
スケジューリングと退避
1 - Kubernetesのスケジューラー
Kubernetesにおいて、スケジューリング とは、KubeletがPodを稼働させるためにNodeに割り当てることを意味します。
スケジューリングの概要
スケジューラーは新規に作成されたPodで、Nodeに割り当てられていないものを監視します。スケジューラーは発見した各Podのために、稼働させるべき最適なNodeを見つけ出す責務を担っています。そのスケジューラーは下記で説明するスケジューリングの原理を考慮に入れて、NodeへのPodの割り当てを行います。
Podが特定のNodeに割り当てられる理由を理解したい場合や、カスタムスケジューラーを自身で作ろうと考えている場合、このページはスケジューリングに関して学ぶのに役立ちます。
kube-scheduler
kube-schedulerはKubernetesにおけるデフォルトのスケジューラーで、コントロールプレーンの一部分として稼働します。 kube-schedulerは、もし希望するのであれば自分自身でスケジューリングのコンポーネントを実装でき、それを代わりに使用できるように設計されています。
kube-schedulerは、新規に作成された各Podや他のスケジューリングされていないPodを稼働させるために最適なNodeを選択します。 しかし、Pod内の各コンテナにはそれぞれ異なるリソースの要件があり、各Pod自体にもそれぞれ異なる要件があります。そのため、既存のNodeは特定のスケジューリング要求によってフィルターされる必要があります。
クラスター内でPodに対する割り当て要求を満たしたNodeは 割り当て可能 なNodeと呼ばれます。 もし適切なNodeが一つもない場合、スケジューラーがNodeを割り当てることができるまで、そのPodはスケジュールされずに残ります。
スケジューラーはPodに対する割り当て可能なNodeをみつけ、それらの割り当て可能なNodeにスコアをつけます。その中から最も高いスコアのNodeを選択し、Podに割り当てるためのいくつかの関数を実行します。 スケジューラーは binding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったNodeの情報を通知します。
スケジューリングを決定する上で考慮が必要な要素としては、個別または複数のリソース要求や、ハードウェア/ソフトウェアのポリシー制約、affinityやanti-affinityの設定、データの局所性や、ワークロード間での干渉などが挙げられます。
kube-schedulerによるスケジューリング
kube-schedulerは2ステップの操作によってPodに割り当てるNodeを選択します。
フィルタリング
スコアリング
フィルタリング ステップでは、Podに割り当て可能なNodeのセットを探します。例えばPodFitsResourcesフィルターは、Podのリソース要求を満たすのに十分なリソースをもつNodeがどれかをチェックします。このステップの後、候補のNodeのリストは、要求を満たすNodeを含みます。 たいてい、リストの要素は複数となります。もしこのリストが空の場合、そのPodはスケジュール可能な状態とはなりません。
スコアリング ステップでは、Podを割り当てるのに最も適したNodeを選択するために、スケジューラーはリストの中のNodeをランク付けします。 スケジューラーは、フィルタリングによって選ばれた各Nodeに対してスコアを付けます。このスコアはアクティブなスコア付けのルールに基づいています。
最後に、kube-schedulerは最も高いランクのNodeに対してPodを割り当てます。もし同一のスコアのNodeが複数ある場合は、kube-schedulerがランダムに1つ選択します。
スケジューラーのフィルタリングとスコアリングの動作に関する設定には2つのサポートされた手法があります。
- スケジューリングポリシー は、フィルタリングのための Predicates とスコアリングのための Priorities の設定することができます。
- スケジューリングプロファイルは、
QueueSort、Filter、Score、Bind、Reserve、Permitやその他を含む異なるスケジューリングの段階を実装するプラグインを設定することができます。kube-schedulerを異なるプロファイルを実行するように設定することもできます。
次の項目
- スケジューラーのパフォーマンスチューニングを参照してください。
- Podトポロジーの分散制約を参照してください。
- kube-schedulerのリファレンスドキュメントを参照してください。
- 複数のスケジューラーの設定について学んでください。
- トポロジーの管理ポリシーについて学んでください。
- Podのオーバーヘッドについて学んでください。
- ボリュームを使用するPodのスケジューリングについて以下で学んでください。
2 - Node上へのPodのスケジューリング
Podを特定のNodeで実行するように 制限 したり、特定のNodeで実行することを 優先 させたりといった制約をかけることができます。 これを実現するためにはいくつかの方法がありますが、推奨されている方法は、すべてラベルセレクターを使用して選択を容易にすることです。 多くの場合、このような制約を設定する必要はなく、スケジューラーが自動的に妥当な配置を行います(例えば、Podを複数のNodeに分散させ、空きリソースが十分でないNodeにPodを配置しないようにすることができます)。 しかし、例えばSSDが接続されているNodeにPodが配置されるようにしたり、多くの通信を行う2つの異なるサービスのPodを同じアベイラビリティーゾーンに配置したりする等、どのNodeに配置するかを制御したい状況もあります。
Kubernetesが特定のPodの配置場所を選択するために、以下の方法があります:
- nodeラベルに対してマッチングを行うnodeSelectorフィールド
- アフィニティとアンチアフィニティ
- nodeNameフィールド
- Podのトポロジー分散制約
Nodeラベル
他の多くのKubernetesオブジェクトと同様に、Nodeにもラベルがあります。手動でラベルを付けることができます。 また、Kubernetesはクラスター内のすべてのNodeに対し、いくつかの標準ラベルを付けます。Nodeラベルの一覧についてはよく使われるラベル、アノテーションとtaintを参照してください。
kubernetes.io/hostnameの値はある環境ではNode名と同じになり、他の環境では異なる値になることがあります。Nodeの分離/制限
Nodeにラベルを追加することで、Podを特定のNodeまたはNodeグループ上でのスケジューリングの対象にすることができます。この機能を使用すると、特定のPodが一定の独立性、安全性、または規制といった属性を持ったNode上でのみ実行されるようにすることができます。
Node分離するのにラベルを使用する場合、kubeletが修正できないラベルキーを選択してください。 これにより、侵害されたNodeが自身でそれらのラベルを設定することで、スケジューラーがそのNodeにワークロードをスケジュールしてしまうのを防ぐことができます。
NodeRestrictionアドミッションプラグインは、kubeletがnode-restriction.kubernetes.io/というプレフィックスを持つラベルを設定または変更するのを防ぎます。
ラベルプレフィックスをNode分離に利用するには:
- Node認可を使用していることと、
NodeRestrictionアドミッションプラグインが 有効 になっていることを確認します。 node-restriction.kubernetes.io/プレフィックスを持つラベルをNodeに追加し、 nodeSelectorでそれらのラベルを使用します。 例えば、example.com.node-restriction.kubernetes.io/fips=trueやexample.com.node-restriction.kubernetes.io/pci-dss=trueなどです。
nodeSelector
nodeSelectorは、Node選択制約の中で最もシンプルな推奨形式です。
Podのspec(仕様)にnodeSelectorフィールドを追加することで、ターゲットNodeが持つべきNodeラベルを指定できます。
Kubernetesは指定された各ラベルを持つNodeにのみ、Podをスケジューリングします。
詳しい情報についてはPodをNodeに割り当てるを参照してください。
アフィニティとアンチアフィニティ
nodeSelectorはPodを特定のラベルが付与されたNodeに制限する最も簡単な方法です。
アフィニティとアンチアフィニティでは、定義できる制約の種類が拡張されています。
アフィニティとアンチアフィニティのメリットは以下の通りです。
- アフィニティとアンチアフィニティで使われる言語は、より表現力が豊かです。
nodeSelectorは指定されたラベルを全て持つNodeを選択するだけです。アフィニティとアンチアフィニティは選択ロジックをより細かく制御することができます。 - ルールが柔軟であったり優先での指定ができたりするため、一致するNodeが見つからない場合でも、スケジューラーはPodをスケジュールします。
- Node自体のラベルではなく、Node(または他のトポロジカルドメイン)上で稼働している他のPodのラベルを使ってPodを制約することができます。これにより、Node上にどのPodを共存させるかのルールを定義することができます。
アフィニティ機能は、2種類のアフィニティで構成されています:
- Nodeアフィニティは
nodeSelectorフィールドと同様に機能しますが、より表現力が豊かで、より柔軟にルールを指定することができます。 - Pod間アフィニティとアンチアフィニティは、他のPodのラベルを元に、Podを制約することができます。
Nodeアフィニティ
Nodeアフィニティは概念的には、NodeのラベルによってPodがどのNodeにスケジュールされるかを制限するnodeSelectorと同様です。
Nodeアフィニティには2種類あります:
requiredDuringSchedulingIgnoredDuringExecution: スケジューラーは、ルールが満たされない限り、Podをスケジュールすることができません。これはnodeSelectorと同じように機能しますが、より表現力豊かな構文になっています。preferredDuringSchedulingIgnoredDuringExecution: スケジューラーは、対応するルールを満たすNodeを探そうとします。 一致するNodeが見つからなくても、スケジューラーはPodをスケジュールします。
IgnoredDuringExecutionは、KubernetesがPodをスケジュールした後にNodeラベルが変更されても、Podは実行し続けることを意味します。Podのspec(仕様)にある.spec.affinity.nodeAffinityフィールドを使用して、Nodeアフィニティを指定することができます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:

apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0この例では、以下のルールが適用されます:
- Nodeには
topology.kubernetes.io/zoneをキーとするラベルが必要で、そのラベルの値はantarctica-east1またはantarctica-west1のいずれかでなければなりません。 - Nodeにはキー名が
another-node-label-keyで、値がanother-node-label-valueのラベルを持つことが望ましいです。
operatorフィールドを使用して、Kubernetesがルールを解釈する際に使用できる論理演算子を指定することができます。In、NotIn、Exists、DoesNotExist、Gt、Ltが使用できます。
NotInとDoesNotExistを使って、Nodeのアンチアフィニティ動作を定義することができます。また、NodeのTaintを使用して、特定のNodeからPodをはじくこともできます。
nodeSelectorとnodeAffinityの両方を指定した場合、両方の条件を満たさないとPodはNodeにスケジュールされません。
nodeAffinityタイプに関連付けられたnodeSelectorTerms内に、複数の条件を指定した場合、Podは指定した条件のいずれかを満たしたNodeへスケジュールされます(条件はORされます)。
nodeSelectorTerms内の条件に関連付けられた1つのmatchExpressionsフィールド内に、複数の条件を指定した場合、Podは全ての条件を満たしたNodeへスケジュールされます(条件はANDされます)。
詳細についてはNodeアフィニティを利用してPodをNodeに割り当てるを参照してください。
Nodeアフィニティの重み
preferredDuringSchedulingIgnoredDuringExecutionアフィニティタイプの各インスタンスに、1から100の範囲のweightを指定できます。
Podの他のスケジューリング要件をすべて満たすNodeを見つけると、スケジューラーはそのNodeが満たすすべての優先ルールを繰り返し実行し、対応する式のweight値を合計に加算します。
最終的な合計は、そのNodeの他の優先度関数のスコアに加算されます。合計スコアが最も高いNodeが、スケジューラーがPodのスケジューリングを決定する際に優先されます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion: v1
kind: Pod
metadata:
name: with-affinity-anti-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: label-1
operator: In
values:
- key-1
- weight: 50
preference:
matchExpressions:
- key: label-2
operator: In
values:
- key-2
containers:
- name: with-node-affinity
image: registry.k8s.io/pause:2.0preferredDuringSchedulingIgnoredDuringExecutionルールにマッチするNodeとして、一つはlabel-1:key-1ラベル、もう一つはlabel-2:key-2ラベルの2つの候補がある場合、スケジューラーは各Nodeのweightを考慮し、その重みとNodeの他のスコアを加え、最終スコアが最も高いNodeにPodをスケジューリングします。
kubernetes.io/os=linuxラベルを持つ既存のNodeが必要です。スケジューリングプロファイルごとのNodeアフィニティ
Kubernetes v1.20 [beta]複数のスケジューリングプロファイルを設定する場合、プロファイルにNodeアフィニティを関連付けることができます。これは、プロファイルが特定のNode群にのみ適用される場合に便利です。スケジューラーの設定にあるNodeAffinityプラグインのargsフィールドにaddedAffinityを追加すると実現できます。例えば:
apiVersion: kubescheduler.config.k8s.io/v1beta3
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: foo-scheduler
pluginConfig:
- name: NodeAffinity
args:
addedAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: scheduler-profile
operator: In
values:
- foo
addedAffinityは、Podの仕様(spec)で指定されたNodeアフィニティに加え、.spec.schedulerNameをfoo-schedulerに設定したすべてのPodに適用されます。つまり、Podにマッチするためには、NodeはaddedAffinityとPodの.spec.NodeAffinityを満たす必要があるのです。
addedAffinityはエンドユーザーには見えないので、その動作はエンドユーザーにとって予期しないものになる可能性があります。スケジューラープロファイル名と明確な相関関係のあるNodeラベルを使用すべきです。
nodeAffinityルールに優先して従います。Pod間のアフィニティとアンチアフィニティ
Pod間のアフィニティとアンチアフィニティは、Nodeのラベルではなく、すでにNode上で稼働しているPodのラベルに従って、PodがどのNodeにスケジュールされるかを制限できます。
XはNodeや、ラック、クラウドプロバイダーのゾーンやリージョン等を表すトポロジードメインで、YはKubernetesが満たそうとするルールである場合、Pod間のアフィニティとアンチアフィニティのルールは、"XにてルールYを満たすPodがすでに稼働している場合、このPodもXで実行すべき(アンチアフィニティの場合はすべきではない)"という形式です。
これらのルール(Y)は、オプションの関連する名前空間のリストを持つラベルセレクターで表現されます。PodはKubernetesの名前空間オブジェクトであるため、Podラベルも暗黙的に名前空間を持ちます。Kubernetesが指定された名前空間でラベルを探すため、Podラベルのラベルセレクターは、名前空間を指定する必要があります。
トポロジードメイン(X)はtopologyKeyで表現され、システムがドメインを示すために使用するNodeラベルのキーになります。具体例はよく知られたラベル、アノテーションとTaintを参照してください。
topologyKeyに合致する適切なラベルが必要になります。
一部、または全部のNodeにtopologyKeyラベルが指定されていない場合、意図しない挙動に繋がる可能性があります。Pod間のアフィニティとアンチアフィニティの種類
Nodeアフィニティと同様に、Podアフィニティとアンチアフィニティにも下記の2種類があります:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
例えば、requiredDuringSchedulingIgnoredDuringExecutionアフィニティを使用して、2つのサービスのPodはお互いのやり取りが多いため、同じクラウドプロバイダーゾーンに併置するようにスケジューラーに指示することができます。
同様に、preferredDuringSchedulingIgnoredDuringExecutionアンチアフィニティを使用して、あるサービスのPodを複数のクラウドプロバイダーゾーンに分散させることができます。
Pod間アフィニティを使用するには、Pod仕様(spec)のaffinity.podAffinityフィールドで指定します。Pod間アンチアフィニティを使用するには、Pod仕様(spec)のaffinity.podAntiAffinityフィールドで指定します。
Podアフィニティ使用例
次のようなPod仕様(spec)を考えてみましょう:
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
この例では、PodアフィニティルールとPodアンチアフィニティルールを1つずつ定義しています。
Podアフィニティルールは"ハード"なrequiredDuringSchedulingIgnoredDuringExecutionを使用し、アンチアフィニティルールは"ソフト"なpreferredDuringSchedulingIgnoredDuringExecutionを使用しています。
アフィニティルールは、スケジューラーがNodeにPodをスケジュールできるのは、そのNodeが、security=S1ラベルを持つ1つ以上の既存のPodと同じゾーンにある場合のみであることを示しています。より正確には、現在Podラベルsecurity=S1を持つPodが1つ以上あるNodeが、そのゾーン内に少なくとも1つ存在する限り、スケジューラーはtopology.kubernetes.io/zone=Vラベルを持つNodeにPodを配置しなければなりません。
アンチアフィニティルールは、security=S2ラベルを持つ1つ以上のPodと同じゾーンにあるNodeには、スケジューラーがPodをスケジュールしないようにすることを示しています。より正確には、PodラベルSecurity=S2を持つPodが稼働している他のNodeが、同じゾーン内に存在する場合、スケジューラーはtopology.kubernetes.io/zone=Rラベルを持つNodeにはPodを配置しないようにしなければなりません。
Podアフィニティとアンチアフィニティの使用例についてもっと知りたい方はデザイン案を参照してください。
Podアフィニティとアンチアフィニティのoperatorフィールドで使用できるのは、In、NotIn、 Exists、 DoesNotExistです。
原則として、topologyKeyには任意のラベルキーが指定できますが、パフォーマンスやセキュリティの観点から、以下の例外があります:
- Podアフィニティとアンチアフィニティでは、
requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecution内のどちらも、topologyKeyフィールドが空であることは許可されていません。 - Podアンチアフィニティルールの
requiredDuringSchedulingIgnoredDuringExecutionでは、アドミッションコントローラーLimitPodHardAntiAffinityTopologyがtopologyKeyをkubernetes.io/hostnameに制限しています。アドミッションコントローラーを修正または無効化すると、トポロジーのカスタマイズができるようになります。
labelSelectorとtopologyKeyに加え、labelSelectorとtopologyKeyと同じレベルのnamespacesフィールドを使用して、labelSelectorが合致すべき名前空間のリストを任意に指定することができます。省略または空の場合、namespacesがデフォルトで、アフィニティとアンチアフィニティが定義されたPodの名前空間に設定されます。
名前空間セレクター
Kubernetes v1.24 [stable]namespaceSelectorを使用し、ラベルで名前空間の集合に対して検索することによって、名前空間を選択することができます。
アフィニティ項はnamespaceSelectorとnamespacesフィールドによって選択された名前空間に適用されます。
要注意なのは、空のnamespaceSelector({})はすべての名前空間にマッチし、nullまたは空のnamespacesリストとnullのnamespaceSelectorは、ルールが定義されているPodの名前空間にマッチします。
実践的なユースケース
Pod間アフィニティとアンチアフィニティは、ReplicaSet、StatefulSet、Deploymentなどのより高レベルなコレクションと併せて使用するとさらに有用です。これらのルールにより、ワークロードのセットが同じ定義されたトポロジーに併置されるように設定できます。たとえば、2つの関連するPodを同じNodeに配置することが好ましい場合です。
例えば、3つのNodeで構成されるクラスターを想像してください。そのクラスターを使用してウェブアプリケーションを実行し、さらにインメモリーキャッシュ(Redisなど)を使用します。この例では、ウェブアプリケーションとメモリーキャッシュの間のレイテンシーは実用的な範囲の低さも想定しています。Pod間アフィニティやアンチアフィニティを使って、ウェブサーバーとキャッシュをなるべく同じ場所に配置することができます。
以下のRedisキャッシュのDeploymentの例では、各レプリカはラベルapp=storeが付与されています。podAntiAffinityルールは、app=storeラベルを持つ複数のレプリカを単一Nodeに配置しないよう、スケジューラーに指示します。これにより、各キャッシュが別々のNodeに作成されます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
app: store
replicas: 3
template:
metadata:
labels:
app: store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
次のウェブサーバーのDeployment例では、app=web-storeラベルが付与されたレプリカを作成します。Podアフィニティルールは、各レプリカを、app=storeラベルが付与されたPodを持つNodeに配置するようスケジューラーに指示します。Podアンチアフィニティルールは、1つのNodeに複数のapp=web-storeサーバーを配置しないようにスケジューラーに指示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
上記2つのDeploymentが生成されると、以下のようなクラスター構成になり、各ウェブサーバーはキャッシュと同位置に、3つの別々のNodeに配置されます。
| node-1 | node-2 | node-3 |
|---|---|---|
| webserver-1 | webserver-2 | webserver-3 |
| cache-1 | cache-2 | cache-3 |
全体的な効果として、各キャッシュインスタンスは、同じNode上で実行している単一のクライアントによってアクセスされる可能性が高いです。この方法は、スキュー(負荷の偏り)とレイテンシーの両方を最小化することを目的としています。
Podアンチアフィニティを使用する理由は他にもあります。 この例と同様の方法で、アンチアフィニティを用いて高可用性を実現したStatefulSetの使用例はZooKeeperチュートリアルを参照してください。
nodeName
nodeNameはアフィニティやnodeSelectorよりも直接的なNode選択形式になります。nodeNameはPod仕様(spec)内のフィールドです。nodeNameフィールドが空でない場合、スケジューラーはPodを考慮せずに、指定されたNodeにあるkubeletがそのNodeにPodを配置しようとします。nodeNameを使用すると、nodeSelectorやアフィニティおよびアンチアフィニティルールを使用するよりも優先されます。
nodeNameを使ってNodeを選択する場合の制約は以下の通りです:
- 指定されたNodeが存在しない場合、Podは実行されず、場合によっては自動的に削除されることがあります。
- 指定されたNodeがPodを収容するためのリソースを持っていない場合、Podの起動は失敗し、OutOfmemoryやOutOfcpuなどの理由が表示されます。
- クラウド環境におけるNode名は、常に予測可能で安定したものではありません。
nodeNameは、カスタムスケジューラーや、設定済みのスケジューラーをバイパスする必要がある高度なユースケースで使用することを目的としています。
スケジューラーをバイパスすると、割り当てられたNodeに過剰なPodの配置をしようとした場合には、Podの起動に失敗することがあります。
NodeアフィニティまたはnodeSelectorフィールドを使用すれば、スケジューラーをバイパスせずに、特定のNodeにPodを割り当てることができます。以下は、nodeNameフィールドを使用したPod仕様(spec)の例になります:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
上記のPodはkube-01というNodeでのみ実行されます。
Podトポロジー分散制約
トポロジー分散制約 を使って、リージョン、ゾーン、Nodeなどの障害ドメイン間、または定義したその他のトポロジードメイン間で、クラスター全体にどのようにPodを分散させるかを制御することができます。これにより、パフォーマンス、予想される可用性、または全体的な使用率を向上させることができます。
詳しい仕組みについては、トポロジー分散制約を参照してください。
次の項目
- TaintとTolerationについてもっと読む。
- NodeアフィニティとPod間アフィニティ/アンチアフィニティのデザインドキュメントを読む。
- トポロジーマネージャーがNodeレベルのリソース割り当ての決定にどのように関与しているかについて学ぶ。
- nodeSelectorの使用方法について学ぶ。
- アフィニティとアンチアフィニティの使用方法について学ぶ。
3 - Podのオーバーヘッド
Kubernetes v1.24 [stable]PodをNode上で実行する時に、Pod自身は大量のシステムリソースを消費します。これらのリソースは、Pod内のコンテナ(群)を実行するために必要なリソースとして追加されます。Podのオーバーヘッドは、コンテナの要求と制限に加えて、Podのインフラストラクチャで消費されるリソースを計算するための機能です。
Kubernetesでは、PodのRuntimeClassに関連するオーバーヘッドに応じて、アドミッション時にPodのオーバーヘッドが設定されます。
Podのオーバーヘッドを有効にした場合、Podのスケジューリング時にコンテナのリソース要求の合計に加えて、オーバーヘッドも考慮されます。同様に、Kubeletは、Podのcgroupのサイズ決定時およびPodの退役の順位付け時に、Podのオーバーヘッドを含めます。
Podのオーバーヘッドの有効化
クラスター全体でPodOverheadのフィーチャーゲートが有効になっていること(1.18時点ではデフォルトでオンになっています)と、overheadフィールドを定義するRuntimeClassが利用されていることを確認する必要があります。
使用例
Podのオーバーヘッド機能を使用するためには、overheadフィールドが定義されたRuntimeClassが必要です。例として、仮想マシンとゲストOSにPodあたり約120MiBを使用する仮想化コンテナランタイムで、次のようなRuntimeClassを定義できます。
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: kata-fc
handler: kata-fc
overhead:
podFixed:
memory: "120Mi"
cpu: "250m"
kata-fcRuntimeClassハンドラーを指定して作成されたワークロードは、リソースクォータの計算や、Nodeのスケジューリング、およびPodのcgroupのサイズ決定にメモリーとCPUのオーバーヘッドが考慮されます。
次のtest-podのワークロードの例を実行するとします。
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
runtimeClassName: kata-fc
containers:
- name: busybox-ctr
image: busybox:1.28
stdin: true
tty: true
resources:
limits:
cpu: 500m
memory: 100Mi
- name: nginx-ctr
image: nginx
resources:
limits:
cpu: 1500m
memory: 100Mi
アドミッション時、RuntimeClassアドミッションコントローラーは、RuntimeClass内に記述されたオーバーヘッドを含むようにワークロードのPodSpecを更新します。もし既にPodSpec内にこのフィールドが定義済みの場合、そのPodは拒否されます。この例では、RuntimeClassの名前しか指定されていないため、アドミッションコントローラーはオーバーヘッドを含むようにPodを変更します。
RuntimeClassのアドミッションコントローラーの後、更新されたPodSpecを確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.overhead}'
出力は次の通りです:
map[cpu:250m memory:120Mi]
ResourceQuotaが定義されている場合、コンテナ要求の合計とオーバーヘッドフィールドがカウントされます。
kube-schedulerが新しいPodを実行すべきNodeを決定する際、スケジューラーはそのPodのオーバーヘッドと、そのPodに対するコンテナ要求の合計を考慮します。この例だと、スケジューラーは、要求とオーバーヘッドを追加し、2.25CPUと320MiBのメモリを持つNodeを探します。
PodがNodeにスケジュールされると、そのNodeのkubeletはPodのために新しいcgroupを生成します。基盤となるコンテナランタイムがコンテナを作成するのは、このPod内です。
リソースにコンテナごとの制限が定義されている場合(制限が定義されているGuaranteed QoSまたはBustrable QoS)、kubeletはそのリソース(CPUはcpu.cfs_quota_us、メモリはmemory.limit_in_bytes)に関連するPodのcgroupの上限を設定します。この上限は、コンテナの制限とPodSpecで定義されたオーバーヘッドの合計に基づきます。
CPUについては、PodがGuaranteedまたはBurstable QoSの場合、kubeletはコンテナの要求の合計とPodSpecに定義されたオーバーヘッドに基づいてcpu.shareを設定します。
次の例より、ワークロードに対するコンテナの要求を確認できます。
kubectl get pod test-pod -o jsonpath='{.spec.containers[*].resources.limits}'
コンテナの要求の合計は、CPUは2000m、メモリーは200MiBです。
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Nodeで観測される値と比較してみましょう。
kubectl describe node | grep test-pod -B2
出力では、2250mのCPUと320MiBのメモリーが要求されており、Podのオーバーヘッドが含まれていることが分かります。
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Podのcgroupの制限を確認
ワークロードで実行中のNode上にある、Podのメモリーのcgroupを確認します。次に示す例では、CRI互換のコンテナランタイムのCLIを提供するNodeでcrictlを使用しています。これはPodのオーバーヘッドの動作を示すための高度な例であり、ユーザーがNode上で直接cgroupsを確認する必要はありません。
まず、特定のNodeで、Podの識別子を決定します。
# PodがスケジュールされているNodeで実行
POD_ID="$(sudo crictl pods --name test-pod -q)"
ここから、Podのcgroupのパスが決定します。
# PodがスケジュールされているNodeで実行
sudo crictl inspectp -o=json $POD_ID | grep cgroupsPath
結果のcgroupパスにはPodのポーズ中コンテナも含まれます。Podレベルのcgroupは1つ上のディレクトリです。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
今回のケースでは、Podのcgroupパスは、kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2となります。メモリーのPodレベルのcgroupの設定を確認しましょう。
# PodがスケジュールされているNodeで実行
# また、Podに割り当てられたcgroupと同じ名前に変更
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
予想通り320MiBです。
335544320
Observability
Podのオーバヘッドが利用されているタイミングを特定し、定義されたオーバーヘッドで実行されているワークロードの安定性を観察するため、kube-state-metricsにはkube_pod_overheadというメトリクスが用意されています。この機能はv1.9のkube-state-metricsでは利用できませんが、次のリリースで期待されています。それまでは、kube-state-metricsをソースからビルドする必要があります。
次の項目
4 - TaintとToleration
Nodeアフィニティは Podの属性であり、あるNode群を引きつけます(優先条件または必須条件)。反対に taint はNodeがある種のPodを排除できるようにします。
toleration はPodに適用され、一致するtaintが付与されたNodeへPodがスケジューリングされることを認めるものです。ただしそのNodeへ必ずスケジューリングされるとは限りません。
taintとtolerationは組になって機能し、Podが不適切なNodeへスケジューリングされないことを保証します。taintはNodeに一つまたは複数個付与することができます。これはそのNodeがtaintを許容しないPodを受け入れるべきではないことを示します。
コンセプト
Nodeにtaintを付与するにはkubectl taintコマンドを使用します。 例えば、次のコマンドは
kubectl taint nodes node1 key1=value1:NoSchedule
node1にtaintを設定します。このtaintのキーはkey1、値はvalue1、taintの効果はNoScheduleです。
これはnode1にはPodに合致するtolerationがなければスケジューリングされないことを意味します。
上記のコマンドで付与したtaintを外すには、下記のコマンドを使います。
kubectl taint nodes node1 key1=value1:NoSchedule-
PodのtolerationはPodSpecの中に指定します。下記のtolerationはどちらも、上記のkubectl taintコマンドで追加したtaintと合致するため、どちらのtolerationが設定されたPodもnode1へスケジューリングされることができます。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
tolerationを設定したPodの例を示します。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "example-key"
operator: "Exists"
effect: "NoSchedule"
operatorのデフォルトはEqualです。
tolerationがtaintと合致するのは、keyとeffectが同一であり、さらに下記の条件のいずれかを満たす場合です。
operatorがExists(valueを指定すべきでない場合)operatorがEqualであり、かつvalueが同一である場合
2つ特殊な場合があります。
空のkeyと演算子Existsは全てのkey、value、effectと一致するため、すべてのtaintと合致します。
空のeffectはkey1が一致する全てのeffectと合致します。
上記の例ではeffectにNoScheduleを指定しました。代わりに、effectにPreferNoScheduleを指定することができます。
これはNoScheduleの「ソフトな」バージョンであり、システムはtaintに対応するtolerationが設定されていないPodがNodeへ配置されることを避けようとしますが、必須の条件とはしません。3つ目のeffectの値としてNoExecuteがありますが、これについては後述します。
同一のNodeに複数のtaintを付与することや、同一のPodに複数のtolerationを設定することができます。 複数のtaintやtolerationが設定されている場合、Kubernetesはフィルタのように扱います。最初はNodeの全てのtaintがある状態から始め、Podが対応するtolerationを持っているtaintは無視され外されていきます。無視されずに残ったtaintが効果を及ぼします。 具体的には、
- effect
NoScheduleのtaintが無視されず残った場合、KubernetesはそのPodをNodeへスケジューリングしません。 - effect
NoScheduleのtaintは残らず、effectPreferNoScheduleのtaintは残った場合、KubernetesはそのNodeへのスケジューリングをしないように試みます。 - effect
NoExecuteのtaintが残った場合、既に稼働中のPodはそのNodeから排除され、まだ稼働していないPodはスケジューリングされないようになります。
例として、下記のようなtaintが付与されたNodeを考えます。
kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
Podには2つのtolerationが設定されています。
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
この例では、3つ目のtaintと合致するtolerationがないため、PodはNodeへはスケジューリングされません。
しかし、これらのtaintが追加された時点で、そのNodeでPodが稼働していれば続けて稼働することが可能です。 これは、Podのtolerationと合致しないtaintは3つあるtaintのうちの3つ目のtaintのみであり、それがNoScheduleであるためです。
一般に、effect NoExecuteのtaintがNodeに追加されると、合致するtolerationが設定されていないPodは即時にNodeから排除され、合致するtolerationが設定されたPodが排除されることは決してありません。
しかし、effectNoExecuteに対するtolerationはtolerationSecondsフィールドを任意で指定することができ、これはtaintが追加された後にそのNodeにPodが残る時間を示します。例えば、
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
この例のPodが稼働中で、対応するtaintがNodeへ追加された場合、PodはそのNodeに3600秒残り、その後排除されます。仮にtaintがそれよりも前に外された場合、Podは排除されません。
ユースケースの例
taintとtolerationは、実行されるべきではないNodeからPodを遠ざけたり、排除したりするための柔軟な方法です。いくつかのユースケースを示します。
専有Node: あるNode群を特定のユーザーに専有させたい場合、そのNode群へtaintを追加し(
kubectl taint nodes nodename dedicated=groupName:NoSchedule) 対応するtolerationをPodへ追加します(これを実現する最も容易な方法はカスタム アドミッションコントローラーを書くことです)。 tolerationが設定されたPodはtaintの設定された(専有の)Nodeと、クラスターにあるその他のNodeの使用が認められます。もしPodが必ず専有Nodeのみを使うようにしたい場合は、taintと同様のラベルをそのNode群に設定し(例:dedicated=groupName)、アドミッションコントローラーはNodeアフィニティを使ってPodがdedicated=groupNameのラベルの付いたNodeへスケジューリングすることが必要であるということも設定する必要があります。特殊なハードウェアを備えるNode: クラスターの中の少数のNodeが特殊なハードウェア(例えばGPU)を備える場合、そのハードウェアを必要としないPodがスケジューリングされないようにして、後でハードウェアを必要とするPodができたときの余裕を確保したいことがあります。 これは特殊なハードウェアを持つNodeにtaintを追加(例えば
kubectl taint nodes nodename special=true:NoScheduleまたはkubectl taint nodes nodename special=true:PreferNoSchedule)して、ハードウェアを使用するPodに対応するtolerationを追加することで可能です。 専有Nodeのユースケースと同様に、tolerationを容易に適用する方法はカスタム アドミッションコントローラーを使うことです。 例えば、特殊なハードウェアを表すために拡張リソース を使い、ハードウェアを備えるNodeに拡張リソースの名称のtaintを追加して、 拡張リソースtoleration アドミッションコントローラーを実行することが推奨されます。Nodeにはtaintが付与されているため、tolerationのないPodはスケジューリングされません。しかし拡張リソースを要求するPodを作成しようとすると、拡張リソースtolerationアドミッションコントローラーはPodに自動的に適切なtolerationを設定し、Podはハードウェアを備えるNodeへスケジューリングされます。 これは特殊なハードウェアを備えたNodeではそれを必要とするPodのみが稼働し、Podに対して手作業でtolerationを追加しなくて済むようにします。taintを基にした排除: Nodeに問題が起きたときにPodごとに排除する設定を行うことができます。次のセクションにて説明します。
taintを基にした排除
Kubernetes v1.18 [stable]上述したように、effect NoExecuteのtaintはNodeで実行中のPodに次のような影響を与えます。
- 対応するtolerationのないPodは即座に除外される
- 対応するtolerationがあり、それに
tolerationSecondsが指定されていないPodは残り続ける - 対応するtolerationがあり、それに
tolerationSecondsが指定されているPodは指定された間、残される
Nodeコントローラーは特定の条件を満たす場合に自動的にtaintを追加します。 組み込まれているtaintは下記の通りです。
node.kubernetes.io/not-ready: Nodeの準備ができていない場合。これはNodeConditionReadyがFalseである場合に対応します。node.kubernetes.io/unreachable: NodeがNodeコントローラーから到達できない場合。これはNodeConditionReadyがUnknownの場合に対応します。node.kubernetes.io/out-of-disk: Nodeのディスクの空きがない場合。node.kubernetes.io/memory-pressure: Nodeのメモリーが不足している場合。node.kubernetes.io/disk-pressure: Nodeのディスクが不足している場合。node.kubernetes.io/network-unavailable: Nodeのネットワークが利用できない場合。node.kubernetes.io/unschedulable: Nodeがスケジューリングできない場合。node.cloudprovider.kubernetes.io/uninitialized: kubeletが外部のクラウド事業者により起動されたときに設定されるtaintで、このNodeは利用不可能であることを示します。cloud-controller-managerによるコントローラーがこのNodeを初期化した後にkubeletはこのtaintを外します。
Nodeから追い出すときには、Nodeコントローラーまたはkubeletは関連するtaintをNoExecute効果の状態で追加します。
不具合のある状態から通常の状態へ復帰した場合は、kubeletまたはNodeコントローラーは関連するtaintを外すことができます。
PodにtolerationSecondsを指定することで不具合があるか応答のないNodeに残る時間を指定することができます。
例えば、ローカルの状態を多数持つアプリケーションとネットワークが分断された場合を考えます。ネットワークが復旧して、Podを排除しなくて済むことを見込んで、長時間Nodeから排除されないようにしたいこともあるでしょう。 この場合Podに設定するtolerationは次のようになります。
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
Kubernetesはユーザーまたはコントローラーが明示的に指定しない限り、自動的にnode.kubernetes.io/not-readyとnode.kubernetes.io/unreachableに対するtolerationをtolerationSeconds=300にて設定します。
自動的に設定されるtolerationは、taintに対応する問題がNodeで検知されても5分間はそのNodeにPodが残されることを意味します。
DaemonSetのPodは次のtaintに対してNoExecuteのtolerationがtolerationSecondsを指定せずに設定されます。
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
これはDaemonSetのPodはこれらの問題によって排除されないことを保証します。
条件によるtaintの付与
NodeのライフサイクルコントローラーはNodeの状態に応じてNoSchedule効果のtaintを付与します。
スケジューラーはNodeの状態ではなく、taintを確認します。
Nodeに何がスケジューリングされるかは、そのNodeの状態に影響されないことを保証します。ユーザーは適切なtolerationをPodに付与することで、どの種類のNodeの問題を無視するかを選ぶことができます。
DaemonSetのコントローラーは、DaemonSetが中断されるのを防ぐために自動的に次のNoScheduletolerationを全てのDaemonSetに付与します。
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk(重要なPodのみ)node.kubernetes.io/unschedulable(1.10またはそれ以降)node.kubernetes.io/network-unavailable(ホストネットワークのみ)
これらのtolerationを追加することは後方互換性を保証します。DaemonSetに任意のtolerationを加えることもできます。
次の項目
5 - スケジューリングフレームワーク
Kubernetes v1.19 [stable]スケジューリングフレームワークはKubernetesのスケジューラーに対してプラグイン可能なアーキテクチャです。 このアーキテクチャは、既存のスケジューラーに新たに「プラグイン」としてAPI群を追加するもので、プラグインはスケジューラー内部にコンパイルされます。このAPI群により、スケジューリングの「コア」の軽量かつ保守しやすい状態に保ちながら、ほとんどのスケジューリングの機能をプラグインとして実装することができます。このフレームワークの設計に関する技術的な情報についてはこちらのスケジューリングフレームワークの設計提案をご覧ください。
フレームワークのワークフロー
スケジューリングフレームワークは、いくつかの拡張点を定義しています。スケジューラープラグインは、1つ以上の拡張点で呼び出されるように登録します。これらのプラグインの中には、スケジューリングの決定を変更できるものから、単に情報提供のみを行うだけのものなどがあります。
この1つのPodをスケジュールしようとする各動作はScheduling CycleとBinding Cycleの2つのフェーズに分けられます。
Scheduling Cycle & Binding Cycle
Scheduling CycleではPodが稼働するNodeを決定し、Binding Cycleではそれをクラスターに適用します。この2つのサイクルを合わせて「スケジューリングコンテキスト」と呼びます。
Scheduling CycleではPodに対して1つ1つが順番に実行され、Binding Cyclesでは並列に実行されます。
Podがスケジューリング不能と判断された場合や、内部エラーが発生した場合、Scheduling CycleまたはBinding Cycleを中断することができます。その際、Podはキューに戻され再試行されます。
拡張点
次の図はPodに対するスケジューリングコンテキストとスケジューリングフレームワークが公開する拡張点を示しています。この図では「Filter」がフィルタリングのための「Predicate」、「Scoring」がスコアリングのための「Priorities」機能に相当します。
1つのプラグインを複数の拡張点に登録することで、より複雑なタスクやステートフルなタスクを実行することができます。
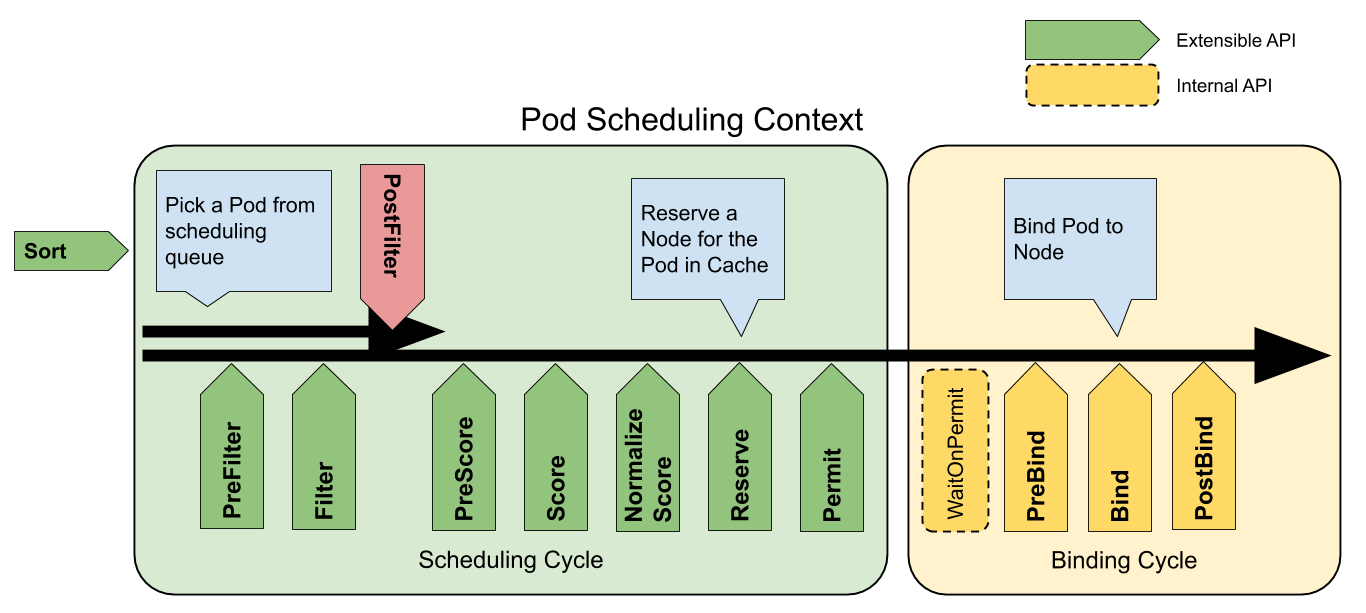
scheduling framework extension points
QueueSort
これらのプラグインはスケジューリングキュー内のPodをソートするために使用されます。このプラグインは、基本的にLess(Pod1, Pod2)という関数を提供します。また、このプラグインは、1つだけ有効化できます。
PreFilter
これらのプラグインは、Podに関する情報を前処理したり、クラスターやPodが満たすべき特定の条件をチェックするために使用されます。もし、PreFilterプラグインのいずれかがエラーを返した場合、Scheduling Cycleは中断されます。
Filter
FilterプラグインはPodを実行できないNodeを候補から除外します。各Nodeに対して、スケジューラーは設定された順番でFilterプラグインを呼び出します。もし、いずれかのFilterプラグインが途中でそのNodeを実行不可能とした場合、残りのプラグインではそのNodeは呼び出されません。Nodeは同時に評価されることがあります。
PostFilter
これらのプラグインはFilterフェーズで、Podに対して実行可能なNodeが見つからなかった場合にのみ呼び出されます。このプラグインは設定された順番で呼び出されます。もしいずれかのPostFilterプラグインが、あるNodeを「スケジュール可能(Schedulable)」と目星をつけた場合、残りのプラグインは呼び出されません。典型的なPostFilterの実装はプリエンプション方式で、他のPodを先取りして、Podをスケジューリングできるようにしようとします。
PreScore
これらのプラグインは、Scoreプラグインが使用する共有可能な状態を生成する「スコアリングの事前」作業を行うために使用されます。このプラグインがエラーを返した場合、Scheduling Cycleは中断されます。
Score
これらのプラグインはフィルタリングのフェーズを通過したNodeをランク付けするために使用されます。スケジューラーはそれぞれのNodeに対して、それぞれのscoringプラグインを呼び出します。スコアの最小値と最大値の範囲が明確に定義されます。NormalizeScoreフェーズの後、スケジューラーは設定されたプラグインの重みに従って、全てのプラグインからNodeのスコアを足し合わせます。
NormalizeScore
これらのプラグインはスケジューラーが最終的なNodeの順位を計算する前にスコアを修正するために使用されます。この拡張点に登録されたプラグインは、同じプラグインのScoreの結果を使用して呼び出されます。各プラグインはScheduling Cycle毎に、1回呼び出されます。
例えば、BlinkingLightScorerというプラグインが、点滅する光の数に基づいてランク付けをするとします。
func ScoreNode(_ *v1.pod, n *v1.Node) (int, error) {
return getBlinkingLightCount(n)
}
ただし、NodeScoreMaxに比べ、点滅をカウントした最大値の方が小さい場合があります。これを解決するために、BlinkingLightScorerも拡張点に登録する必要があります。
func NormalizeScores(scores map[string]int) {
highest := 0
for _, score := range scores {
highest = max(highest, score)
}
for node, score := range scores {
scores[node] = score*NodeScoreMax/highest
}
}
NormalizeScoreプラグインが途中でエラーを返した場合、Scheduling Cycleは中断されます。
Reserve
Reserve拡張を実装したプラグインには、ReserveとUnreserve という2つのメソッドがあり、それぞれReserve
とUnreserveと呼ばれる2つの情報スケジューリングフェーズを返します。
実行状態を保持するプラグイン(別名「ステートフルプラグイン」)は、これらのフェーズを使用して、Podに対してNodeのリソースが予約されたり予約解除された場合に、スケジューラーから通知を受け取ります。
Reserveフェーズは、スケジューラーが実際にPodを指定されたNodeにバインドする前に発生します。このフェーズはスケジューラーがバインドが成功するのを待つ間にレースコンディションの発生を防ぐためにあります。
各ReserveプラグインのReserveメソッドは成功することも失敗することもあります。もしどこかのReserveメソッドの呼び出しが失敗すると、後続のプラグインは実行されず、Reserveフェーズは失敗したものとみなされます。全てのプラグインのReserveメソッドが成功した場合、Reserveフェーズは成功とみなされ、残りのScheduling CycleとBinding Cycleが実行されます。
Unreserveフェーズは、Reserveフェーズまたは後続のフェーズが失敗した場合に、呼び出されます。この時、全てのReserveプラグインのUnreserveメソッドが、Reserveメソッドの呼び出された逆の順序で実行されます。このフェーズは予約されたPodに関連する状態をクリーンアップするためにあります。
Unreserveメソッドの実装は冪等性を持つべきであり、この処理で問題があった場合に失敗させてはなりません。Permit
Permit プラグインは、各PodのScheduling Cycleの終了時に呼び出され、候補Nodeへのバインドを阻止もしくは遅延させるために使用されます。permitプラグインは次の3つのうちどれかを実行できます。
承認(approve)
全てのPermitプラグインから承認(approve)されたPodは、バインド処理へ送られます。拒否(deny)
もしどれか1つのPermitプラグインがPodを拒否(deny)した場合、そのPodはスケジューリングキューに戻されます。 これはReserveプラグイン内のUnreserveフェーズで呼び出されます。待機(wait) (タイムアウトあり)
もしPermitプラグインが「待機(wait)」を返した場合、そのPodは内部の「待機中」Podリストに保持され、このPodに対するBinding Cycleは開始されるものの、承認(approve)されるまで直接ブロックされます。もしタイムアウトが発生した場合、この待機(wait)はdenyへ変わり、対象のPodはスケジューリングキューに戻されると共に、ReserveプラグインのUnreserveフェーズが呼び出されます。
FrameworkHandle)、その中の予約済みPodのバインドを承認(approve)できるのはPermitプラグインだけであると予想します。承認(approve)されたPodは、PreBindフェーズへ送られます。PreBind
これらのプラグインは、Podがバインドされる前に必要な作業を行うために使用されます。例えば、Podの実行を許可する前に、ネットワークボリュームをプロビジョニングし、Podを実行予定のNodeにマウントすることができます。
もし、いずれかのPreBindプラグインがエラーを返した場合、Podは拒否され、スケジューリングキューに戻されます。
Bind
これらのプラグインはPodをNodeにバインドするために使用されます。このプラグインは全てのPreBindプラグインの処理が完了するまで呼ばれません。それぞれのBindプラグインは設定された順序で呼び出されます。このプラグインは、与えられたPodを処理するかどうかを選択することができます。もしPodを処理することを選択した場合、残りのBindプラグインは全てスキップされます。
PostBind
これは単に情報提供のための拡張点です。Post-bindプラグインはPodのバインドが成功した後に呼び出されます。これはBinding Cycleの最後であり、関連するリソースのクリーンアップに使用されます。
プラグインAPI
プラグインAPIには2つの段階があります。まず、プラグインを登録し設定することです。そして、拡張点インターフェースを使用することです。このインターフェースは次のような形式をとります。
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*v1.pod, *v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter(context.Context, *framework.CycleState, *v1.pod) error
}
// ...
プラグインの設定
スケジューラーの設定でプラグインを有効化・無効化することができます。Kubernetes v1.18以降を使用しているなら、ほとんどのスケジューリングプラグインは使用されており、デフォルトで有効になっています。
デフォルトのプラグインに加えて、独自のスケジューリングプラグインを実装し、デフォルトのプラグインと一緒に使用することも可能です。詳しくはスケジューラープラグインをご覧下さい。
Kubernetes v1.18以降を使用しているなら、プラグインのセットをスケジューラープロファイルとして設定し、様々な種類のワークロードに適合するように複数のプロファイルを定義することが可能です。詳しくは複数のプロファイルをご覧下さい。
6 - スケジューラーのパフォーマンスチューニング
Kubernetes 1.14 [beta]kube-schedulerはKubernetesのデフォルトのスケジューラーです。クラスター内のノード上にPodを割り当てる責務があります。
クラスター内に存在するノードで、Podのスケジューリング要求を満たすものはPodに対して割り当て可能なノードと呼ばれます。スケジューラーはPodに対する割り当て可能なノードをみつけ、それらの割り当て可能なノードにスコアをつけます。その中から最も高いスコアのノードを選択し、Podに割り当てるためのいくつかの関数を実行します。スケジューラーはBindingと呼ばれる処理中において、APIサーバーに対して割り当てが決まったノードの情報を通知します。
このページでは、大規模のKubernetesクラスターにおけるパフォーマンス最適化のためのチューニングについて説明します。
大規模クラスターでは、レイテンシー(新規Podをすばやく配置)と精度(スケジューラーが不適切な配置を行うことはめったにありません)の間でスケジューリング結果を調整するスケジューラーの動作をチューニングできます。
このチューニング設定は、kube-scheduler設定のpercentageOfNodesToScoreで設定できます。KubeSchedulerConfiguration設定は、クラスター内のノードにスケジュールするための閾値を決定します。
閾値の設定
percentageOfNodesToScoreオプションは、0から100までの数値を受け入れます。0は、kube-schedulerがコンパイル済みのデフォルトを使用することを示す特別な値です。
percentageOfNodesToScoreに100より大きな値を設定した場合、kube-schedulerの挙動は100を設定した場合と同様となります。
この値を変更するためには、kube-schedulerの設定ファイル(これは/etc/kubernetes/config/kube-scheduler.yamlの可能性が高い)を編集し、スケジューラーを再起動します。
この変更をした後、
kubectl get pods -n kube-system | grep kube-scheduler
を実行して、kube-schedulerコンポーネントが正常であることを確認できます。
ノードへのスコア付けの閾値
スケジューリング性能を改善するため、kube-schedulerは割り当て可能なノードが十分に見つかるとノードの検索を停止できます。大規模クラスターでは、すべてのノードを考慮する単純なアプローチと比較して時間を節約できます。
クラスター内のすべてのノードに対する十分なノード数を整数パーセンテージで指定します。kube-schedulerは、これをノード数に変換します。スケジューリング中に、kube-schedulerが設定されたパーセンテージを超える十分な割り当て可能なノードを見つけた場合、kube-schedulerはこれ以上割り当て可能なノードを探すのを止め、スコアリングフェーズに進みます。
スケジューラーはどのようにノードを探索するかで処理を詳しく説明しています。
デフォルトの閾値
閾値を指定しない場合、Kubernetesは100ノードのクラスターでは50%、5000ノードのクラスターでは10%になる線形方程式を使用して数値を計算します。自動計算の下限は5%です。
つまり、明示的にpercentageOfNodesToScoreを5未満の値を設定しない限り、クラスターの規模に関係なく、kube-schedulerは常に少なくともクラスターの5%のノードに対してスコア付けをします。
スケジューラーにクラスター内のすべてのノードに対してスコア付けをさせる場合は、percentageOfNodesToScoreの値に100を設定します。
例
percentageOfNodesToScoreの値を50%に設定する例は下記のとおりです。
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
algorithmSource:
provider: DefaultProvider
...
percentageOfNodesToScore: 50
percentageOfNodesToScoreのチューニング
percentageOfNodesToScoreは1から100の間の範囲である必要があり、デフォルト値はクラスターのサイズに基づいて計算されます。また、クラスターのサイズの最小値は50ノードとハードコードされています。
割り当て可能なノードが50以下のクラスターでは、スケジューラの検索を早期に停止するのに十分な割り当て可能なノードがないため、スケジューラはすべてのノードをチェックします。
小規模クラスターでは、percentageOfNodesToScoreに低い値を設定したとしても、同様の理由で変更による影響は全くないか、ほとんどありません。
クラスターのノード数が数百以下の場合は、この設定オプションをデフォルト値のままにします。変更してもスケジューラの性能を大幅に改善する可能性はほとんどありません。
この値を設定する際に考慮するべき重要な注意事項として、割り当て可能ノードのチェック対象のノードが少ないと、一部のノードはPodの割り当てのためにスコアリングされなくなります。結果として、高いスコアをつけられる可能性のあるノードがスコアリングフェーズに渡されることがありません。これにより、Podの配置が理想的なものでなくなります。
kube-schedulerが頻繁に不適切なPodの配置を行わないよう、percentageOfNodesToScoreをかなり低い値を設定することは避けるべきです。スケジューラのスループットがアプリケーションにとって致命的で、ノードのスコアリングが重要でない場合を除いて、10%未満に設定することは避けてください。言いかえると、割り当て可能な限り、Podは任意のノード上で稼働させるのが好ましいです。
スケジューラーはどのようにノードを探索するか
このセクションでは、この機能の内部の詳細を理解したい人向けになります。
クラスター内の全てのノードに対して平等にPodの割り当ての可能性を持たせるため、スケジューラーはラウンドロビン方式でノードを探索します。複数のノードの配列になっているイメージです。スケジューラーはその配列の先頭から探索を開始し、percentageOfNodesToScoreによって指定された数のノードを検出するまで、割り当て可能かどうかをチェックしていきます。次のPodでは、スケジューラーは前のPodの割り当て処理でチェックしたところから探索を再開します。
ノードが複数のゾーンに存在するとき、スケジューラーは様々なゾーンのノードを探索して、異なるゾーンのノードが割り当て可能かどうかのチェック対象になるようにします。例えば2つのゾーンに6つのノードがある場合を考えます。
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
スケジューラーは、下記の順番でノードの割り当て可能性を評価します。
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
全てのノードのチェックを終えたら、1番目のノードに戻ってチェックをします。
7 - 拡張リソースのリソースビンパッキング
Kubernetes v1.16 [alpha]kube-schedulerでは、優先度関数RequestedToCapacityRatioResourceAllocationを使用した、
拡張リソースを含むリソースのビンパッキングを有効化できます。優先度関数はそれぞれのニーズに応じて、kube-schedulerを微調整するために使用できます。
RequestedToCapacityRatioResourceAllocationを使用したビンパッキングの有効化
Kubernetesでは、キャパシティー比率への要求に基づいたNodeのスコアリングをするために、各リソースの重みと共にリソースを指定することができます。これにより、ユーザーは適切なパラメーターを使用することで拡張リソースをビンパックすることができ、大規模クラスターにおける希少なリソースを有効活用できるようになります。優先度関数RequestedToCapacityRatioResourceAllocationの動作はRequestedToCapacityRatioArgsと呼ばれる設定オプションによって変わります。この引数はshapeとresourcesパラメーターによって構成されます。shapeパラメーターはutilizationとscoreの値に基づいて、最も要求が多い場合か最も要求が少ない場合の関数をチューニングできます。resourcesパラメーターは、スコアリングの際に考慮されるリソース名のnameと、各リソースの重みを指定するweightで構成されます。
以下は、拡張リソースintel.com/fooとintel.com/barのビンパッキングにrequestedToCapacityRatioArgumentsを設定する例になります。
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
profiles:
# ...
pluginConfig:
- name: RequestedToCapacityRatio
args:
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resources:
- name: intel.com/foo
weight: 3
- name: intel.com/bar
weight: 5
スケジューラーには、kube-schedulerフラグ--config=/path/to/config/fileを使用してKubeSchedulerConfigurationのファイルを指定することで渡すことができます。
この機能はデフォルトで無効化されています
優先度関数のチューニング
shapeはRequestedToCapacityRatioPriority関数の動作を指定するために使用されます。
shape:
- utilization: 0
score: 0
- utilization: 100
score: 10
上記の引数は、utilizationが0%の場合は0、utilizationが100%の場合は10というscoreをNodeに与え、ビンパッキングの動作を有効にしています。最小要求を有効にするには、次のようにスコアを反転させる必要があります。
shape:
- utilization: 0
score: 10
- utilization: 100
score: 0
resourcesはオプションパラメーターで、デフォルトでは以下の通りです。
resources:
- name: cpu
weight: 1
- name: memory
weight: 1
以下のように拡張リソースの追加に利用できます。
resources:
- name: intel.com/foo
weight: 5
- name: cpu
weight: 3
- name: memory
weight: 1
weightはオプションパラメーターで、指定されてない場合1が設定されます。また、マイナスの値は設定できません。
キャパシティ割り当てのためのNodeスコアリング
このセクションは、本機能の内部詳細について理解したい方を対象としています。以下は、与えられた値に対してNodeのスコアがどのように計算されるかの例です。
要求されたリソース:
intel.com/foo : 2
memory: 256MB
cpu: 2
リソースの重み:
intel.com/foo : 5
memory: 1
cpu: 3
shapeの値 {{0, 0}, {100, 10}}
Node1のスペック:
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = (7 * 5) + (5 * 1) + (3 * 3) / (5 + 1 + 3)
= 5
Node2のスペック:
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = (5 * 5) + (7 * 1) + (10 * 3) / (5 + 1 + 3)
= 7
次の項目
- スケジューリングフレームワークについて更に読む
- スケジューラーの設定について更に読む
8 - Podの優先度とプリエンプション
Kubernetes v1.14 [stable]Podは priority(優先度)を持つことができます。 優先度は他のPodに対する相対的なPodの重要度を示します。 もしPodをスケジューリングできないときには、スケジューラーはそのPodをスケジューリングできるようにするため、優先度の低いPodをプリエンプトする(追い出す)ことを試みます。
クラスターの全てのユーザーが信用されていない場合、悪意のあるユーザーが可能な範囲で最も高い優先度のPodを作成することが可能です。これは他のPodが追い出されたりスケジューリングできない状態を招きます。 管理者はResourceQuotaを使用して、ユーザーがPodを高い優先度で作成することを防ぐことができます。
詳細はデフォルトで優先度クラスの消費を制限する を参照してください。
優先度とプリエンプションを使う方法
優先度とプリエンプションを使うには、
1つまたは複数のPriorityClassを追加します
追加したPriorityClassを
priorityClassNameに設定したPodを作成します。 もちろんPodを直接作る必要はありません。 一般的にはpriorityClassNameをDeploymentのようなコレクションオブジェクトのPodテンプレートに追加します。
これらの手順のより詳しい情報については、この先を読み進めてください。
system-cluster-criticalとsystem-node-criticalです。
これらは汎用のクラスであり、重要なコンポーネントが常に最初にスケジュールされることを保証するために使われます。PriorityClass
PriorityClassはnamespaceによらないオブジェクトで、優先度クラスの名称から優先度を表す整数値への対応を定義します。
PriorityClassオブジェクトのメタデータのnameフィールドにて名称を指定します。
値はvalueフィールドで指定し、必須です。
値が大きいほど、高い優先度を示します。
PriorityClassオブジェクトの名称はDNSサブドメイン名として適切であり、かつsystem-から始まってはいけません。
PriorityClassオブジェクトは10億以下の任意の32ビットの整数値を持つことができます。 それよりも大きな値は通常はプリエンプトや追い出すべきではない重要なシステム用のPodのために予約されています。 クラスターの管理者は割り当てたい優先度に対して、PriorityClassオブジェクトを1つずつ作成すべきです。
PriorityClassは任意でフィールドglobalDefaultとdescriptionを設定可能です。
globalDefaultフィールドはpriorityClassNameが指定されないPodはこのPriorityClassを使うべきであることを示します。globalDefaultがtrueに設定されたPriorityClassはシステムで一つのみ存在可能です。globalDefaultが設定されたPriorityClassが存在しない場合は、priorityClassNameが設定されていないPodの優先度は0に設定されます。
descriptionフィールドは任意の文字列です。クラスターの利用者に対して、PriorityClassをどのような時に使うべきか示すことを意図しています。
PodPriorityと既存のクラスターに関する注意
もし既存のクラスターをこの機能がない状態でアップグレードすると、既存のPodの優先度は実質的に0になります。
globalDefaultがtrueに設定されたPriorityClassを追加しても、既存のPodの優先度は変わりません。PriorityClassのそのような値は、PriorityClassが追加された以後に作成されたPodのみに適用されます。PriorityClassを削除した場合、削除されたPriorityClassの名前を使用する既存のPodは変更されませんが、削除されたPriorityClassの名前を使うPodをそれ以上作成することはできなくなります。
PriorityClassの例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "この優先度クラスはXYZサービスのPodに対してのみ使用すべきです。"
非プリエンプトのPriorityClass
Kubernetes v1.24 [stable]preemptionPolicy: Neverと設定されたPodは、スケジューリングのキューにおいて他の優先度の低いPodよりも優先されますが、他のPodをプリエンプトすることはありません。
スケジューリングされるのを待つ非プリエンプトのPodは、リソースが十分に利用可能になるまでスケジューリングキューに残ります。
非プリエンプトのPodは、他のPodと同様に、スケジューラーのバックオフの対象になります。これは、スケジューラーがPodをスケジューリングしようと試みたものの失敗した場合、低い頻度で再試行するようにして、より優先度の低いPodが先にスケジューリングされることを許します。
非プリエンプトのPodは、他の優先度の高いPodにプリエンプトされる可能性はあります。
preemptionPolicyはデフォルトではPreemptLowerPriorityに設定されており、これが設定されているPodは優先度の低いPodをプリエンプトすることを許容します。これは既存のデフォルトの挙動です。
preemptionPolicyをNeverに設定すると、これが設定されたPodはプリエンプトを行わないようになります。
ユースケースの例として、データサイエンスの処理を挙げます。
ユーザーは他の処理よりも優先度を高くしたいジョブを追加できますが、そのとき既存の実行中のPodの処理結果をプリエンプトによって破棄させたくはありません。
preemptionPolicy: Neverが設定された優先度の高いジョブは、他の既にキューイングされたPodよりも先に、クラスターのリソースが「自然に」開放されたときにスケジューリングされます。
非プリエンプトのPriorityClassの例
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-nonpreempting
value: 1000000
preemptionPolicy: Never
globalDefault: false
description: "この優先度クラスは他のPodをプリエンプトさせません。"
Podの優先度
一つ以上のPriorityClassがあれば、仕様にPriorityClassを指定したPodを作成することができるようになります。優先度のアドミッションコントローラーはpriorityClassNameフィールドを使用し、優先度の整数値を設定します。PriorityClassが見つからない場合、そのPodの作成は拒否されます。
下記のYAMLは上記の例で作成したPriorityClassを使用するPodの設定の例を示します。優先度のアドミッションコントローラーは仕様を確認し、このPodの優先度は1000000であると設定します。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
スケジューリング順序におけるPodの優先度の効果
Podの優先度が有効な場合、スケジューラーは待機状態のPodをそれらの優先度順に並べ、スケジューリングキューにおいてより優先度の低いPodよりも前に来るようにします。その結果、その条件を満たしたときには優先度の高いPodは優先度の低いPodより早くスケジューリングされます。優先度の高いPodがスケジューリングできない場合は、スケジューラーは他の優先度の低いPodのスケジューリングも試みます。
プリエンプション
Podが作成されると、スケジューリング待ちのキューに入り待機状態になります。スケジューラーはキューからPodを取り出し、ノードへのスケジューリングを試みます。Podに指定された条件を全て満たすノードが見つからない場合は、待機状態のPodのためにプリエンプションロジックが発動します。待機状態のPodをPと呼ぶことにしましょう。プリエンプションロジックはPよりも優先度の低いPodを一つ以上追い出せばPをスケジューリングできるようになるノードを探します。そのようなノードがあれば、優先度の低いPodはノードから追い出されます。Podが追い出された後に、Pはノードへスケジューリング可能になります。
ユーザーへ開示される情報
Pod PがノードNのPodをプリエンプトした場合、ノードNの名称がPのステータスのnominatedNodeNameフィールドに設定されます。このフィールドはスケジューラーがPod Pのために予約しているリソースの追跡を助け、ユーザーにクラスターにおけるプリエンプトに関する情報を与えます。
Pod Pは必ずしも「指名したノード」へスケジューリングされないことに注意してください。スケジューラーは、他のノードに対して処理を繰り返す前に、常に「指定したノード」に対して試行します。Podがプリエンプトされると、そのPodは終了までの猶予期間を得ます。スケジューラーがPodの終了を待つ間に他のノードが利用可能になると、スケジューラーは他のノードをPod Pのスケジューリング先にすることがあります。この結果、PodのnominatedNodeNameとnodeNameは必ずしも一致しません。また、スケジューラーがノードNのPodをプリエンプトさせた後に、Pod Pよりも優先度の高いPodが来た場合、スケジューラーはノードNをその新しい優先度の高いPodへ与えることもあります。このような場合は、スケジューラーはPod PのnominatedNodeNameを消去します。これによって、スケジューラーはPod Pが他のノードのPodをプリエンプトさせられるようにします。
プリエンプトの制限
プリエンプトされるPodの正常終了
Podがプリエンプトされると、猶予期間が与えられます。 Podは作業を完了し、終了するために十分な時間が与えられます。仮にそうでない場合、強制終了されます。この猶予期間によって、スケジューラーがPodをプリエンプトした時刻と、待機状態のPod Pがノード Nにスケジュール可能になるまでの時刻の間に間が開きます。この間、スケジューラーは他の待機状態のPodをスケジュールしようと試みます。プリエンプトされたPodが終了したら、スケジューラーは待ち行列にあるPodをスケジューリングしようと試みます。そのため、Podがプリエンプトされる時刻と、Pがスケジュールされた時刻には間が開くことが一般的です。この間を最小にするには、優先度の低いPodの猶予期間を0または小さい値にする方法があります。
PodDisruptionBudgetは対応するが、保証されない
PodDisruptionBudget (PDB)は、アプリケーションのオーナーが冗長化されたアプリケーションのPodが意図的に中断される数の上限を設定できるようにするものです。KubernetesはPodをプリエンプトする際にPDBに対応しますが、PDBはベストエフォートで考慮します。スケジューラーはプリエンプトさせたとしてもPDBに違反しないPodを探します。そのようなPodが見つからない場合でもプリエンプションは実行され、PDBに反しますが優先度の低いPodが追い出されます。
優先度の低いPodにおけるPod間のアフィニティ
次の条件が真の場合のみ、ノードはプリエンプションの候補に入ります。 「待機状態のPodよりも優先度の低いPodをノードから全て追い出したら、待機状態のPodをノードへスケジュールできるか」
待機状態のPodが、優先度の低いPodとの間でPod間のアフィニティを持つ場合、Pod間のアフィニティはそれらの優先度の低いPodがなければ満たされません。この場合、スケジューラーはノードのどのPodもプリエンプトしようとはせず、代わりに他のノードを探します。スケジューラーは適切なノードを探せる場合と探せない場合があります。この場合、待機状態のPodがスケジューリングされる保証はありません。
この問題に対して推奨される解決策は、優先度が同一または高いPodに対してのみPod間のアフィニティを作成することです。
複数ノードに対するプリエンプション
Pod PがノードNにスケジューリングできるよう、ノードNがプリエンプションの対象となったとします。 他のノードのPodがプリエンプトされた場合のみPが実行可能になることもあります。下記に例を示します。
- Pod PをノードNに配置することを検討します。
- Pod QはノードNと同じゾーンにある別のノードで実行中です。
- Pod Pはゾーンに対するQへのアンチアフィニティを持ちます (
topologyKey: topology.kubernetes.io/zone)。 - Pod Pと、ゾーン内の他のPodに対しては他のアンチアフィニティはない状態です。
- Pod PをノードNへスケジューリングするには、Pod Qをプリエンプトすることが考えられますが、スケジューラーは複数ノードにわたるプリエンプションは行いません。そのため、Pod PはノードNへはスケジューリングできないとみなされます。
Pod Qがそのノードから追い出されると、Podアンチアフィニティに違反しなくなるので、Pod PはノードNへスケジューリング可能になります。
複数ノードに対するプリエンプションに関しては、十分な需要があり、合理的な性能を持つアルゴリズムを見つけられた場合に、将来的に機能追加を検討する可能性があります。
トラブルシューティング
Podの優先度とプリエンプションは望まない副作用をもたらす可能性があります。 いくつかの起こりうる問題と、その対策について示します。
Podが不必要にプリエンプトされる
プリエンプションは、リソースが不足している場合に優先度の高い待機状態のPodのためにクラスターの既存のPodを追い出します。
誤って高い優先度をPodに割り当てると、意図しない高い優先度のPodはクラスター内でプリエンプションを引き起こす可能性があります。Podの優先度はPodの仕様のpriorityClassNameフィールドにて指定されます。優先度を示す整数値へと変換された後、podSpecのpriorityへ設定されます。
この問題に対処するには、PodのpriorityClassNameをより低い優先度に変更するか、このフィールドを未設定にすることができます。priorityClassNameが未設定の場合、デフォルトでは優先度は0とされます。
Podがプリエンプトされたとき、プリエンプトされたPodのイベントが記録されます。 プリエンプションはPodに必要なリソースがクラスターにない場合のみ起こるべきです。 このような場合、プリエンプションはプリエンプトされるPodよりも待機状態のPodの優先度が高い場合のみ発生します。 プリエンプションは待機状態のPodがない場合や待機状態のPodがプリエンプト対象のPod以下の優先度を持つ場合には決して発生しません。そのような状況でプリエンプションが発生した場合、問題を報告してください。
Podはプリエンプトされたが、プリエンプトさせたPodがスケジューリングされない
Podがプリエンプトされると、それらのPodが要求した猶予期間が与えられます。そのデフォルトは30秒です。 Podがその期間内に終了しない場合、強制終了されます。プリエンプトされたPodがなくなれば、プリエンプトさせたPodはスケジューリング可能です。
プリエンプトさせたPodがプリエンプトされたPodの終了を待っている間に、より優先度の高いPodが同じノードに対して作成されることもあります。この場合、スケジューラーはプリエンプトさせたPodの代わりに優先度の高いPodをスケジューリングします。
これは予期された挙動です。優先度の高いPodは優先度の低いPodに取って代わります。
優先度の高いPodが優先度の低いPodより先にプリエンプトされる
スケジューラーは待機状態のPodが実行可能なノードを探します。ノードが見つからない場合、スケジューラーは任意のノードから優先度の低いPodを追い出し、待機状態のPodのためのリソースを確保しようとします。 仮に優先度の低いPodが動いているノードが待機状態のPodを動かすために適切ではない場合、スケジューラーは他のノードで動いているPodと比べると、優先度の高いPodが動いているノードをプリエンプションの対象に選ぶことがあります。この場合もプリエンプトされるPodはプリエンプトを起こしたPodよりも優先度が低い必要があります。
複数のノードがプリエンプションの対象にできる場合、スケジューラーは優先度が最も低いPodのあるノードを選ぼうとします。しかし、そのようなPodがPodDisruptionBudgetを持っており、プリエンプトするとPDBに反する場合はスケジューラーは優先度の高いPodのあるノードを選ぶこともあります。
複数のノードがプリエンプションの対象として利用可能で、上記の状況に当てはまらない場合、スケジューラーは優先度の最も低いノードを選択します。
Podの優先度とQoSの相互作用
Podの優先度とQoSクラスは直交する機能で、わずかに相互作用がありますが、デフォルトではQoSクラスによる優先度の設定の制約はありません。スケジューラーのプリエンプションのロジックはプリエンプションの対象を決めるときにQoSクラスは考慮しません。
プリエンプションはPodの優先度を考慮し、優先度が最も低いものを候補とします。より優先度の高いPodは優先度の低いPodを追い出すだけではプリエンプトを起こしたPodのスケジューリングに不十分な場合と、PodDisruptionBudgetにより優先度の低いPodが保護されている場合のみ対象になります。
kubeletはnode-pressureによる退避を行うPodの順番を決めるために、優先度を利用します。QoSクラスを使用して、最も退避される可能性の高いPodの順番を推定することができます。 kubeletは追い出すPodの順位付けを次の順で行います。
- 枯渇したリソースを要求以上に使用しているか
- Podの優先度
- 要求に対するリソースの使用量
詳細はkubeletによるPodの退避を参照してください。
kubeletによるリソース不足時のPodの追い出しでは、リソースの消費が要求を超えないPodは追い出されません。優先度の低いPodのリソースの利用量がその要求を超えていなければ、追い出されることはありません。より優先度が高く、要求を超えてリソースを使用しているPodが追い出されます。
次の項目
- PriorityClassと関連付けてResourceQuotaを使用することに関して デフォルトで優先度クラスの消費を制限する
- Podの破壊を読む
- APIを起点とした退避を読む
- Node-pressureによる退避を読む
9 - APIを起点とした退避
APIを起点とした退避は、Eviction APIを使用して退避オブジェクトを作成し、Podの正常終了を起動させるプロセスです。
Eviction APIを直接呼び出すか、kubectl drainコマンドのようにAPIサーバーのクライアントを使って退避を要求することが可能です。これにより、Evictionオブジェクトを作成し、APIサーバーにPodを終了させます。
APIを起点とした退避はPodDisruptionBudgetsとterminationGracePeriodSecondsの設定を優先します。
APIを使用してPodのEvictionオブジェクトを作成することは、Podに対してポリシー制御されたDELETE操作を実行することに似ています。
Eviction APIの実行
Kubernetes APIへアクセスしてEvictionオブジェクトを作るためにKubernetesのプログラミング言語のクライアントを使用できます。
そのためには、次の例のようなデータをPOSTすることで操作を試みることができます。
policy/v1においてEvictionはv1.22以上で利用可能です。それ以前のリリースでは、policy/v1beta1を使用してください。{
"apiVersion": "policy/v1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
policy/v1が採用されました。{
"apiVersion": "policy/v1beta1",
"kind": "Eviction",
"metadata": {
"name": "quux",
"namespace": "default"
}
}
また、以下の例のようにcurlやwgetを使ってAPIにアクセスすることで、操作を試みることもできます。
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
APIを起点とした退避の仕組み
APIを使用して退去を要求した場合、APIサーバーはアドミッションチェックを行い、以下のいずれかを返します。
200 OK:この場合、退去が許可されるとEvictionサブリソースが作成され、PodのURLにDELETEリクエストを送るのと同じように、Podが削除されます。429 Too Many Requests:PodDisruptionBudgetの設定により、現在退去が許可されていないことを示します。しばらく時間を空けてみてください。また、APIのレート制限のため、このようなレスポンスが表示されることもあります。500 Internal Server Error:複数のPodDisruptionBudgetが同じPodを参照している場合など、設定に誤りがあり退去が許可されないことを示します。
退去させたいPodがPodDisruptionBudgetを持つワークロードの一部でない場合、APIサーバーは常に200 OKを返して退去を許可します。
APIサーバーが退去を許可した場合、以下の流れでPodが削除されます。
- APIサーバーの
Podリソースの削除タイムスタンプが更新され、APIサーバーはPodリソースが終了したと見なします。またPodリソースは、設定された猶予期間が設けられます。 - ローカルのPodが動作しているNodeのkubeletは、
Podリソースが終了するようにマークされていることに気付き、Podの適切なシャットダウンを開始します。 - kubeletがPodをシャットダウンしている間、コントロールプレーンはEndpointオブジェクトからPodを削除します。その結果、コントローラーはPodを有効なオブジェクトと見なさないようになります。
- Podの猶予期間が終了すると、kubeletはローカルPodを強制的に終了します。
- kubeletはAPIサーバーに
Podリソースを削除するように指示します。 - APIサーバーは
Podリソースを削除します。
トラブルシューティング
場合によっては、アプリケーションが壊れた状態になり、対処しない限りEviction APIが429または500レスポンスを返すだけとなることがあります。例えば、ReplicaSetがアプリケーション用のPodを作成しても、新しいPodがReady状態にならない場合などです。また、最後に退去したPodの終了猶予期間が長い場合にも、この事象が見られます。
退去が進まない場合は、以下の解決策を試してみてください。
- 問題を引き起こしている自動化された操作を中止または一時停止し、操作を再開する前に、スタックしているアプリケーションを調査を行ってください。
- しばらく待ってから、Eviction APIを使用する代わりに、クラスターのコントロールプレーンから直接Podを削除してください。
次の項目
- Pod Disruption Budgetでアプリケーションを保護する方法について学ぶ
- Node不足による退避について学ぶ
- Podの優先度とプリエンプションについて学ぶ