You are viewing documentation for Kubernetes version: v1.26
Kubernetes v1.26 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date information, see the latest version.
Dynamic Kubelet Configuration
Author: Michael Taufen (Google)
Editor’s note: The feature has been removed in the version 1.24 after deprecation in 1.22.
Editor’s note: this post is part of a series of in-depth articles on what’s new in Kubernetes 1.11
Why Dynamic Kubelet Configuration?
Kubernetes provides API-centric tooling that significantly improves workflows for managing applications and infrastructure. Most Kubernetes installations, however, run the Kubelet as a native process on each host, outside the scope of standard Kubernetes APIs.
In the past, this meant that cluster administrators and service providers could not rely on Kubernetes APIs to reconfigure Kubelets in a live cluster. In practice, this required operators to either ssh into machines to perform manual reconfigurations, use third-party configuration management automation tools, or create new VMs with the desired configuration already installed, then migrate work to the new machines. These approaches are environment-specific and can be expensive.
Dynamic Kubelet configuration gives cluster administrators and service providers the ability to reconfigure Kubelets in a live cluster via Kubernetes APIs.
What is Dynamic Kubelet Configuration?
Kubernetes v1.10 made it possible to configure the Kubelet via a beta config file API. Kubernetes already provides the ConfigMap abstraction for storing arbitrary file data in the API server.
Dynamic Kubelet configuration extends the Node object so that a Node can refer to a ConfigMap that contains the same type of config file. When a Node is updated to refer to a new ConfigMap, the associated Kubelet will attempt to use the new configuration.
How does it work?
Dynamic Kubelet configuration provides the following core features:
- Kubelet attempts to use the dynamically assigned configuration.
- Kubelet "checkpoints" configuration to local disk, enabling restarts without API server access.
- Kubelet reports assigned, active, and last-known-good configuration sources in the Node status.
- When invalid configuration is dynamically assigned, Kubelet automatically falls back to a last-known-good configuration and reports errors in the Node status.
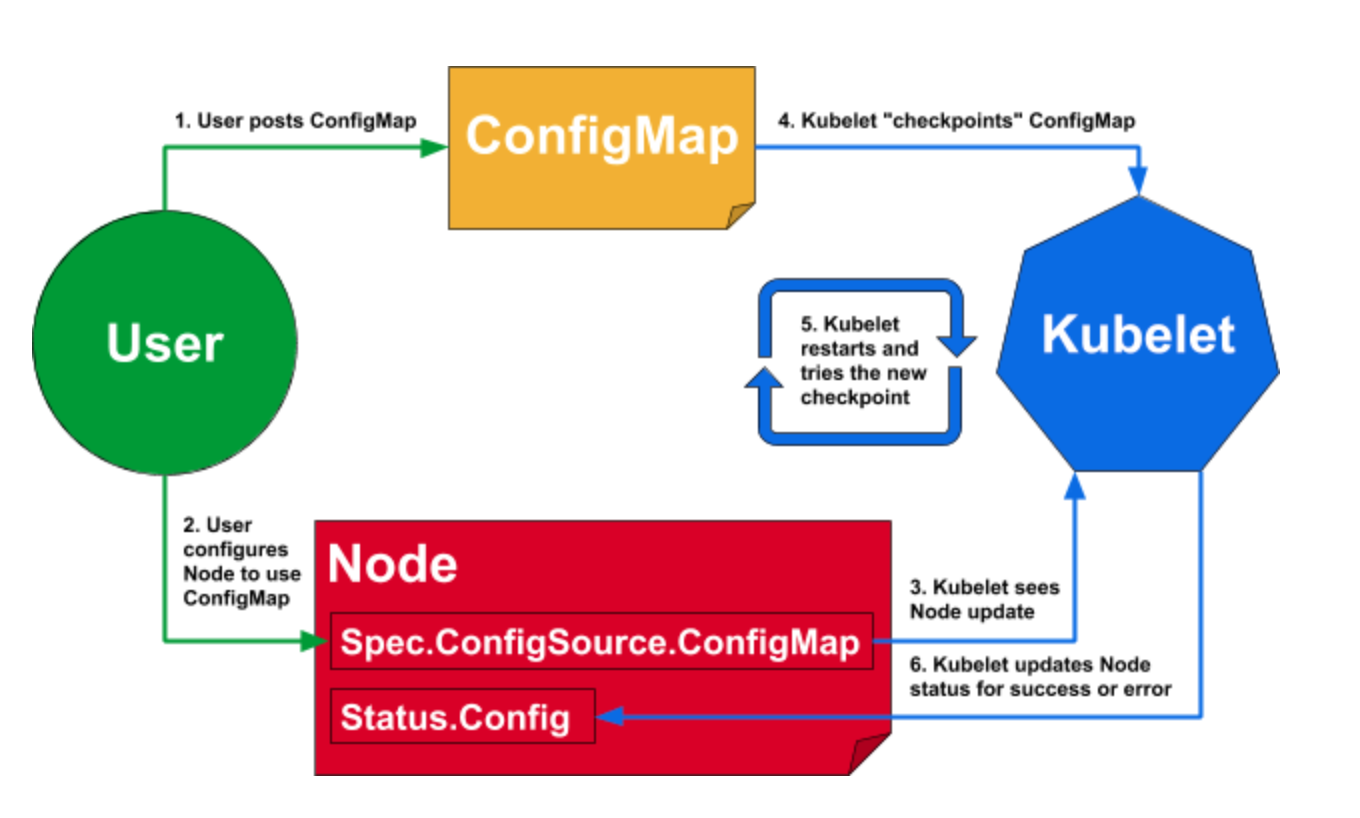
To use the dynamic Kubelet configuration feature, a cluster administrator or service provider will first post a ConfigMap containing the desired configuration, then set each Node.Spec.ConfigSource.ConfigMap reference to refer to the new ConfigMap. Operators can update these references at their preferred rate, giving them the ability to perform controlled rollouts of new configurations.
Each Kubelet watches its associated Node object for changes. When the Node.Spec.ConfigSource.ConfigMap reference is updated, the Kubelet will "checkpoint" the new ConfigMap by writing the files it contains to local disk. The Kubelet will then exit, and the OS-level process manager will restart it. Note that if the Node.Spec.ConfigSource.ConfigMap reference is not set, the Kubelet uses the set of flags and config files local to the machine it is running on.
Once restarted, the Kubelet will attempt to use the configuration from the new checkpoint. If the new configuration passes the Kubelet's internal validation, the Kubelet will update Node.Status.Config to reflect that it is using the new configuration. If the new configuration is invalid, the Kubelet will fall back to its last-known-good configuration and report an error in Node.Status.Config.
Note that the default last-known-good configuration is the combination of Kubelet command-line flags with the Kubelet's local configuration file. Command-line flags that overlap with the config file always take precedence over both the local configuration file and dynamic configurations, for backwards-compatibility.
See the following diagram for a high-level overview of a configuration update for a single Node:
How can I learn more?
Please see the official tutorial at /docs/tasks/administer-cluster/reconfigure-kubelet/, which contains more in-depth details on user workflow, how a configuration becomes "last-known-good," how the Kubelet "checkpoints" config, and possible failure modes.