Kamu sedang menampilkan dokumentasi untuk Kubernetes versi: v1.26
Kubernetes v1.26 dokumentasi sudah tidak dirawat lagi. Versi yang kamu lihat ini hanyalah snapshot statis. Untuk dokumentasi terkini, lihat versi terbaru.
Mengatur Control Plane Kubernetes dengan Ketersediaan Tinggi (High-Availability)
Kubernetes v1.5 [alpha]Kamu dapat mereplikasi control plane Kubernetes dalam skrip kube-up atau kube-down untuk Google Compute Engine (GCE).
Dokumen ini menjelaskan cara menggunakan skrip kube-up/down untuk mengelola control plane dengan ketersedian tinggi atau high_availability (HA) dan bagaimana control plane HA diimplementasikan untuk digunakan dalam GCE.
Sebelum kamu memulai
Kamu harus memiliki klaster Kubernetes, dan perangkat baris perintah kubectl juga harus dikonfigurasikan untuk berkomunikasi dengan klastermu. Jika kamu belum memiliki klaster, kamu dapat membuatnya dengan menggunakan minikube, atau kamu juga dapat menggunakan salah satu dari tempat mencoba Kubernetes berikut ini:
Untuk melihat versi, tekankubectl version.Memulai klaster yang kompatibel dengan HA
Untuk membuat klaster yang kompatibel dengan HA, kamu harus mengatur tanda ini pada skrip kube-up:
MULTIZONE=true- untuk mencegah penghapusan replika control plane kubelet dari zona yang berbeda dengan zona bawaan server. Ini diperlukan jika kamu ingin menjalankan replika control plane pada zona berbeda, dimana hal ini disarankan.ENABLE_ETCD_QUORUM_READ=true- untuk memastikan bahwa pembacaan dari semua server API akan mengembalikan data terbaru. Jikatrue, bacaan akan diarahkan ke replika pemimpin dari etcd. Menetapkan nilai ini menjaditruebersifat opsional: pembacaan akan lebih dapat diandalkan tetapi juga akan menjadi lebih lambat.
Sebagai pilihan, kamu dapat menentukan zona GCE tempat dimana replika control plane pertama akan dibuat. Atur tanda berikut:
KUBE_GCE_ZONE=zone- zona tempat di mana replika control plane pertama akan berjalan.
Berikut ini contoh perintah untuk mengatur klaster yang kompatibel dengan HA pada zona GCE europe-west1-b:
MULTIZONE=true KUBE_GCE_ZONE=europe-west1-b ENABLE_ETCD_QUORUM_READS=true ./cluster/kube-up.sh
Perhatikan bahwa perintah di atas digunakan untuk membuat klaster dengan sebuah control plane; Namun, kamu bisa menambahkan replika control plane baru ke klaster dengan perintah berikutnya.
Menambahkan replika control plane yang baru
Setelah kamu membuat klaster yang kompatibel dengan HA, kamu bisa menambahkan replika control plane ke sana.
Kamu bisa menambahkan replika control plane dengan menggunakan skrip kube-up dengan tanda berikut ini:
KUBE_REPLICATE_EXISTING_MASTER=true- untuk membuat replika dari control plane yang sudah ada.KUBE_GCE_ZONE=zone- zona di mana replika control plane itu berjalan. Region ini harus sama dengan region dari zona replika yang lain.
Kamu tidak perlu mengatur tanda MULTIZONE atau ENABLE_ETCD_QUORUM_READS,
karena tanda itu diturunkan pada saat kamu memulai klaster yang kompatible dengan HA.
Berikut ini contoh perintah untuk mereplikasi control plane pada klaster sebelumnya yang kompatibel dengan HA:
KUBE_GCE_ZONE=europe-west1-c KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
Menghapus replika control plane
Kamu dapat menghapus replika control plane dari klaster HA dengan menggunakan skrip kube-down dengan tanda berikut:
KUBE_DELETE_NODES=false- untuk mencegah penghapusan kubelet.KUBE_GCE_ZONE=zone- zona di mana replika control plane akan dihapus.KUBE_REPLICA_NAME=replica_name- (opsional) nama replika control plane yang akan dihapus. Jika kosong: replika mana saja dari zona yang diberikan akan dihapus.
Berikut ini contoh perintah untuk menghapus replika control plane dari klaster HA yang sudah ada sebelumnya:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=europe-west1-c ./cluster/kube-down.sh
Mengatasi replika control plane yang gagal
Jika salah satu replika control plane di klaster HA kamu gagal, praktek terbaik adalah menghapus replika dari klaster kamu dan menambahkan replika baru pada zona yang sama. Berikut ini contoh perintah yang menunjukkan proses tersebut:
- Menghapus replika yang gagal:
KUBE_DELETE_NODES=false KUBE_GCE_ZONE=replica_zone KUBE_REPLICA_NAME=replica_name ./cluster/kube-down.sh
- Menambahkan replika baru untuk menggantikan replika yang lama
KUBE_GCE_ZONE=replica-zone KUBE_REPLICATE_EXISTING_MASTER=true ./cluster/kube-up.sh
Praktek terbaik untuk mereplikasi control plane untuk klaster HA
Usahakan untuk menempatkan replika control plane pada zona yang berbeda. Pada saat terjadi kegagalan zona, semua control plane yang ditempatkan dalam zona tersebut akan gagal pula. Untuk bertahan dari kegagalan pada sebuah zona, tempatkan juga Node pada beberapa zona yang lain (Lihatlah multi-zona untuk lebih detail).
Jangan gunakan klaster dengan dua replika control plane. Konsensus pada klaster dengan dua replika membutuhkan kedua replika tersebut berjalan pada saat mengubah keadaan yang persisten. Akibatnya, kedua replika tersebut diperlukan dan kegagalan salah satu replika mana pun mengubah klaster dalam status kegagalan mayoritas. Dengan demikian klaster dengan dua replika lebih buruk, dalam hal HA, daripada klaster dengan replika tunggal.
Ketika kamu menambahkan sebuah replika control plane, status klaster (etcd) disalin ke sebuah instance baru. Jika klaster itu besar, mungkin butuh waktu yang lama untuk menduplikasi keadaannya. Operasi ini dapat dipercepat dengan memigrasi direktori data etcd, seperti yang dijelaskan di sini (Kami sedang mempertimbangkan untuk menambahkan dukungan untuk migrasi direktori data etcd di masa mendatang).
Catatan implementasi
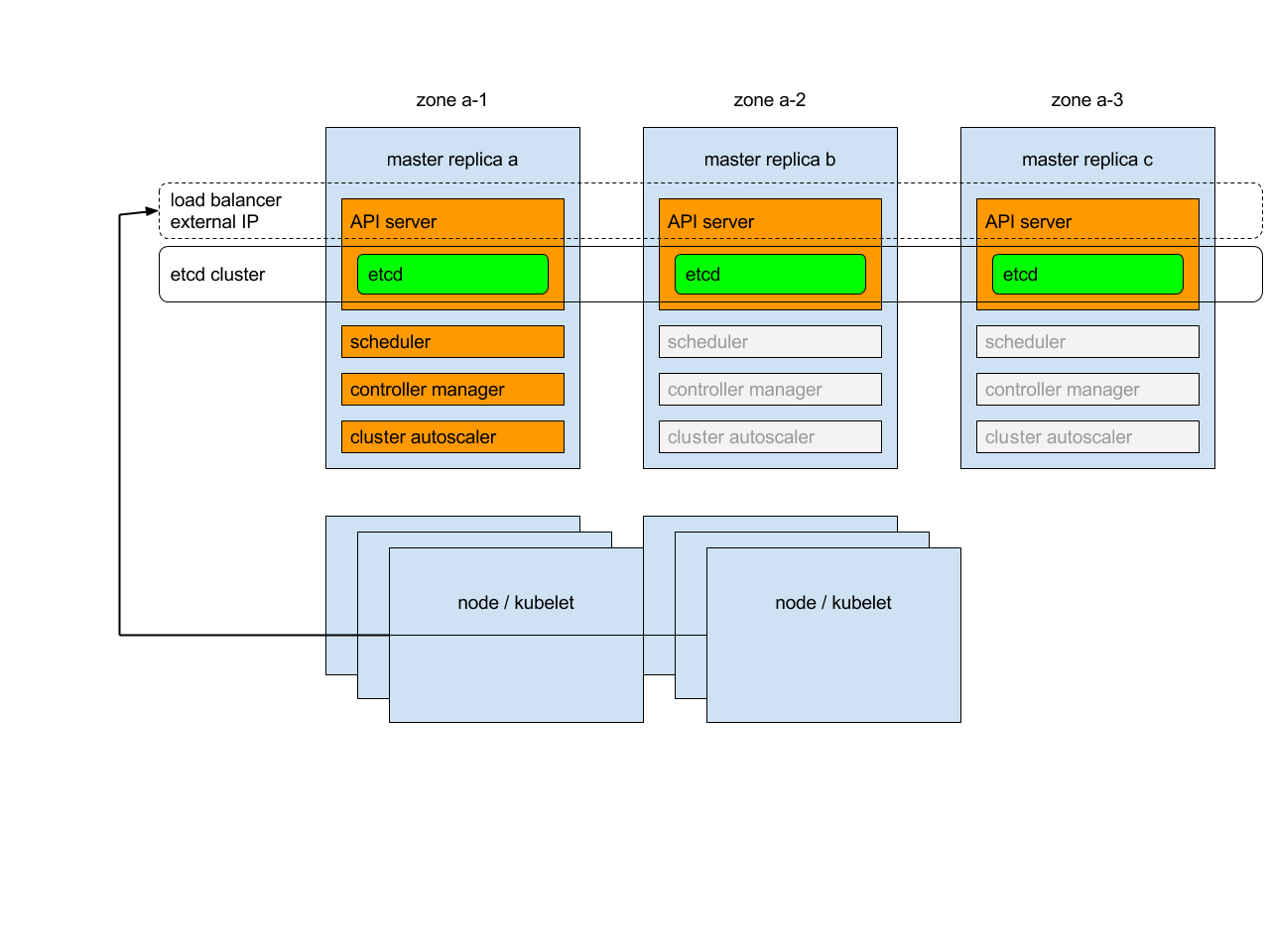
Ikhtisar
Setiap replika control plane akan menjalankan komponen berikut dalam mode berikut:
instance etcd: semua instance akan dikelompokkan bersama menggunakan konsensus;
server API : setiap server akan berbicara dengan lokal etcd - semua server API pada cluster akan tersedia;
pengontrol (controller), penjadwal (scheduler), dan scaler klaster automatis: akan menggunakan mekanisme sewa - dimana hanya satu instance dari masing-masing mereka yang akan aktif dalam klaster;
manajer tambahan (add-on): setiap manajer akan bekerja secara independen untuk mencoba menjaga tambahan dalam sinkronisasi.
Selain itu, akan ada penyeimbang beban (load balancer) di depan server API yang akan mengarahkan lalu lintas eksternal dan internal menuju mereka.
Penyeimbang Beban
Saat memulai replika control plane kedua, penyeimbang beban yang berisi dua replika akan dibuat dan alamat IP dari replika pertama akan dipromosikan ke alamat IP penyeimbang beban. Demikian pula, setelah penghapusan replika control plane kedua yang dimulai dari paling akhir, penyeimbang beban akan dihapus dan alamat IP-nya akan diberikan ke replika terakhir yang ada. Mohon perhatikan bahwa pembuatan dan penghapusan penyeimbang beban adalah operasi yang rumit dan mungkin perlu beberapa waktu (~20 menit) untuk dipropagasikan.
Service control plane & kubelet
Daripada sistem mencoba untuk menjaga daftar terbaru dari apiserver Kubernetes yang ada dalam Service Kubernetes, sistem akan mengarahkan semua lalu lintas ke IP eksternal:
dalam klaster dengan satu control plane, IP diarahkan ke control plane tunggal.
dalam klaster dengan multiple control plane, IP diarahkan ke penyeimbang beban yang ada di depan control plane.
Demikian pula, IP eksternal akan digunakan oleh kubelet untuk berkomunikasi dengan control plane.
Sertifikat control plane
Kubernetes menghasilkan sertifikat TLS control plane untuk IP publik eksternal dan IP lokal untuk setiap replika. Tidak ada sertifikat untuk IP publik sementara (ephemeral) dari replika; Untuk mengakses replika melalui IP publik sementara, kamu harus melewatkan verifikasi TLS.
Pengklasteran etcd
Untuk mengizinkan pengelompokkan etcd, porta yang diperlukan untuk berkomunikasi antara instance etcd akan dibuka (untuk komunikasi dalam klaster). Untuk membuat penyebaran itu aman, komunikasi antara instance etcd diotorisasi menggunakan SSL.